



并发编程框架----Disruptor框架
背景
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能。在美团技术团队它也有不少应用,有的项目架构借鉴了它的设计机制。本文从实战角度剖析了Disruptor的实现原理。
需要特别指出的是,这里所说的队列是系统内部的内存队列,而不是Kafka这样的分布式队列。另外,本文所描述的Disruptor特性限于3.3.4。
依赖
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
Java内置队列
介绍Disruptor之前,我们先来看一看常用的线程安全的内置队列有什么问题。Java的内置队列如下表所示。
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded | 加锁 | arraylist |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedlist |
| ConcurrentLinkedQueue | unbounded | 无锁 | linkedlist |
| LinkedTransferQueue | unbounded | 无锁 | linkedlist |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成LinkedBlockingQueue和ConcurrentLinkedQueue两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的LinkedTransferQueue都是通过原子变量compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
通过不加锁的方式实现的队列都是无界的(无法保证队列的长度在确定的范围内);而加锁的方式,可以实现有界队列。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap格式的数据结构。这样筛选下来,符合条件的队列就只有ArrayBlockingQueue。
ArrayBlockingQueue的问题
ArrayBlockingQueue在实际使用过程中,会因为加锁和伪共享等出现严重的性能问题,我们下面来分析一下
加锁
现实编程过程中,加锁通常会严重地影响性能。线程会因为竞争不到锁而被挂起,等锁被释放的时候,线程又会被恢复,这个过程中存在着很大的开销,并且通常会有较长时间的中断,因为当一个线程正在等待锁时,它不能做任何其他事情。如果一个线程在持有锁的情况下被延迟执行,例如发生了缺页错误、调度延迟或者其它类似情况,那么所有需要这个锁的线程都无法执行下去。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,就会发生优先级反转。
CAS操作比单线程无锁慢了1个数量级;有锁且多线程并发的情况下,速度比单线程无锁慢3个数量级。可见无锁速度最快。
单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能。
在多线程情况下,为了保证线程安全,必须使用CAS或锁,这种情况下,CAS的性能超过锁的性能,前者大约是后者的8倍。
伪共享
ArrayBlockingQueue有三个成员变量: - takeIndex:需要被取走的元素下标 - putIndex:可被元素插入的位置的下标 - count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

这种无法充分使用缓存行特性的现象,称为伪共享。
对于伪共享,一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
关于什么是伪共享参考文章:什么是伪共享
Disruptor的设计方案
Disruptor通过以下设计来解决队列速度慢的问题:
- 环形数组结构
环形数组结构是整个Disruptor的核心所在。
首先因为是数组,所以要比链表快,而且根据我们对上面缓存行的解释知道,数组中的一个元素加载,相邻的数组元素也是会被预加载的,因此在这样的结构中,cpu无需时不时去主存加载数组中的下一个元素。而且,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。环形数组中的元素采用覆盖方式,避免了jvm的GC。
其次结构作为环形,数组的大小为2的n次方,这样元素定位可以通过位运算效率会更高,这个跟一致性哈希中的环形策略有点像。在disruptor中,这个牛逼的环形结构就是RingBuffer,既然是数组,那么就有大小,而且这个大小必须是2的n次方

其实质只是一个普通的数组,只是当放置数据填充满队列(即到达2^n-1位置)之后,再填充数据,就会从0开始,覆盖之前的数据,于是就相当于一个环。
- 元素位置定位
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
- 无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
下面忽略数组的环形结构,介绍一下如何实现无锁设计。整个过程通过原子变量CAS,保证操作的线程安全。
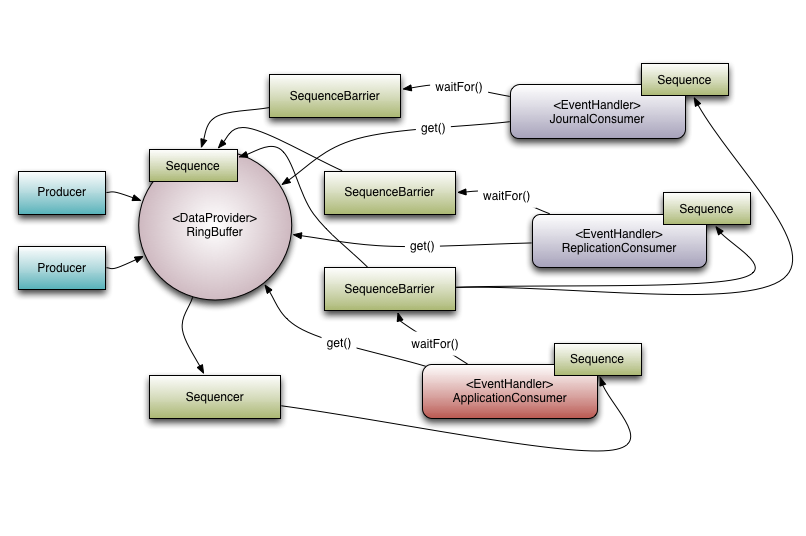
Disruptor的核心概念
先从了解 Disruptor 的核心概念开始,来了解它是如何运作的。下面介绍的概念模型,既是领域对象,也是映射到代码实现上的核心对象。
-
Ring Buffer
如其名,环形的缓冲区。曾经 RingBuffer 是 Disruptor 中的最主要的对象,但从3.0版本开始,其职责被简化为仅仅负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。在一些更高级的应用场景中,Ring Buffer 可以由用户的自定义实现来完全替代。
-
Sequence Disruptor
通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。一个 Sequence 用于跟踪标识某个特定的事件处理者( RingBuffer/Consumer )的处理进度。虽然一个 AtomicLong 也可以用于标识进度,但定义 Sequence 来负责该问题还有另一个目的,那就是防止不同的 Sequence 之间的CPU缓存伪共享(Flase Sharing)问题
-
Sequencer
Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
-
Sequence Barrier
用于保持对RingBuffer的 main published Sequence 和Consumer依赖的其它Consumer的 Sequence 的引用。 Sequence Barrier 还定义了决定 Consumer 是否还有可处理的事件的逻辑。
-
Wait Strategy
定义 Consumer 如何进行等待下一个事件的策略。 (注:Disruptor 定义了多种不同的策略,针对不同的场景,提供了不一样的性能表现)
-
Event
在 Disruptor 的语义中,生产者和消费者之间进行交换的数据被称为事件(Event)。它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor 的使用者定义并指定。
-
EventProcessor
EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。
-
EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。
-
Producer
即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
一个生产者
写数据
生产者单线程写数据的流程比较简单:
- 申请写入m个元素;
- 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。

多个生产者
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
下面分读数据和写数据两种情况介绍。
读数据
生产者多线程写入的情况会复杂很多:
- 申请读取到序号n;
- 若writer cursor >= n,这时仍然无法确定连续可读的最大下标。从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从3到6共计4个元素。

写数据
多个生产者写入的时候:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。

防止不同生产者对同一段空间写入的代码,如下所示:
public long tryNext(int n) throws InsufficientCapacityException
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
return next;
}
通过do/while循环的条件cursor.compareAndSet(current, next),来判断每次申请的空间是否已经被其他生产者占据。假如已经被占据,该函数会返回失败,While循环重新执行,申请写入空间。
示例
以下代码基于3.3.4版本的Disruptor包。
Disruptor 的 API 十分简单,主要有以下几个步骤:
-
定义事件
事件(Event)就是通过 Disruptor 进行交换的数据类型。
public class LongEvent { private long value; public void set(long value) { this.value = value; } } -
定义事件工厂
事件工厂(Event Factory)定义了如何实例化前面第1步中定义的事件(Event),需要实现接口 com.lmax.disruptor.EventFactory
。
Disruptor 通过 EventFactory 在 RingBuffer 中预创建 Event 的实例。
一个 Event 实例实际上被用作一个“数据槽”,发布者发布前,先从 RingBuffer 获得一个 Event 的实例,然后往 Event 实例中填充数据,之后再发布到 RingBuffer 中,之后由 Consumer 获得该 Event 实例并从中读取数据。import com.lmax.disruptor.EventFactory; public class LongEventFactory implements EventFactory<LongEvent> { public LongEvent newInstance() { return new LongEvent(); } } -
定义事件处理的具体实现(这里可以理解为事件的消费者)
通过实现接口 com.lmax.disruptor.EventHandler
定义事件处理的具体实现。 import com.lmax.disruptor.EventHandler; public class LongEventHandler implements EventHandler<LongEvent> { public void onEvent(LongEvent event, long sequence, boolean endOfBatch) { System.out.println("Event: " + event); } } -
定义用于事件处理的线程池
Disruptor 通过 java.util.concurrent.ExecutorService 提供的线程来触发 Consumer 的事件处理。例如:
ExecutorService executor = Executors.newCachedThreadPool(); -
指定等待策略
Disruptor 定义了 com.lmax.disruptor.WaitStrategy 接口用于抽象 Consumer 如何等待新事件,这是策略模式的应用。
Disruptor 提供了多个 WaitStrategy 的实现,每种策略都具有不同性能和优缺点,根据实际运行环境的 CPU 的硬件特点选择恰当的策略,并配合特定的 JVM 的配置参数,能够实现不同的性能提升。
例如,BlockingWaitStrategy、SleepingWaitStrategy、YieldingWaitStrategy 等,其中,
BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现;
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy(); WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy(); WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy(); -
启动 Disruptor
EventFactory<LongEvent> eventFactory = new LongEventFactory(); ExecutorService executor = Executors.newSingleThreadExecutor(); int ringBufferSize = 1024 * 1024; // RingBuffer 大小,必须是 2 的 N 次方; Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor, ProducerType.SINGLE, new YieldingWaitStrategy()); EventHandler<LongEvent> eventHandler = new LongEventHandler(); disruptor.handleEventsWith(eventHandler); disruptor.start(); -
发布事件
Disruptor 的事件发布过程是一个两阶段提交的过程:
第一步:先从 RingBuffer 获取下一个可以写入的事件的序号;
第二步:获取对应的事件对象,将数据写入事件对象;
第三部:将事件提交到 RingBuffer;
事件只有在提交之后才会通知 EventProcessor 进行处理;// 发布事件; RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); long sequence = ringBuffer.next();//请求下一个事件序号; try { LongEvent event = ringBuffer.get(sequence);//获取该序号对应的事件对象; long data = getEventData();//获取要通过事件传递的业务数据; event.set(data); } finally{ ringBuffer.publish(sequence);//发布事件; }注意,最后的 ringBuffer.publish 方法必须包含在 finally 中以确保必须得到调用;如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。
Disruptor 还提供另外一种形式的调用来简化以上操作,并确保 publish 总是得到调用。
static class Translator implements EventTranslatorOneArg<LongEvent, Long>{ @Override public void translateTo(LongEvent event, long sequence, Long data) { event.set(data); } } public static Translator TRANSLATOR = new Translator(); public static void publishEvent2(Disruptor<LongEvent> disruptor) { // 发布事件; RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); long data = getEventData();//获取要通过事件传递的业务数据; ringBuffer.publishEvent(TRANSLATOR, data); } -
关闭 Disruptor
disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理;
executor.shutdown();//关闭 disruptor 使用的线程池;如果需要的话,必须手动关闭, disruptor 在 shutdown 时不会自动关闭;
完整示例代码
package com.meituan.Disruptor;
/**
* @description disruptor代码样例。每10ms向disruptor中插入一个元素,消费者读取数据,并打印到终端
*/
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.ThreadFactory;
public class DisruptorMain
{
public static void main(String[] args) throws Exception
{
// 队列中的元素
class Element {
private int value;
public int get(){
return value;
}
public void set(int value){
this.value= value;
}
}
// 生产者的线程工厂
ThreadFactory threadFactory = new ThreadFactory(){
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "simpleThread");
}
};
// RingBuffer生产工厂,初始化RingBuffer的时候使用
EventFactory<Element> factory = new EventFactory<Element>() {
@Override
public Element newInstance() {
return new Element();
}
};
// 处理Event的handler
EventHandler<Element> handler = new EventHandler<Element>(){
@Override
public void onEvent(Element element, long sequence, boolean endOfBatch)
{
System.out.println("Element: " + element.get());
}
};
// 阻塞策略
BlockingWaitStrategy strategy = new BlockingWaitStrategy();
// 指定RingBuffer的大小
int bufferSize = 16;
// 创建disruptor,采用单生产者模式
Disruptor<Element> disruptor = new Disruptor(factory, bufferSize, threadFactory, ProducerType.SINGLE, strategy);
// 设置EventHandler
disruptor.handleEventsWith(handler);
// 启动disruptor的线程
disruptor.start();
RingBuffer<Element> ringBuffer = disruptor.getRingBuffer();
for (int l = 0; true; l++)
{
// 获取下一个可用位置的下标
long sequence = ringBuffer.next();
try
{
// 返回可用位置的元素
Element event = ringBuffer.get(sequence);
// 设置该位置元素的值
event.set(l);
}
finally
{
ringBuffer.publish(sequence);
}
Thread.sleep(10);
}
}
}
总结
Disruptor通过精巧的无锁设计实现了在高并发情形下的高性能。
在美团内部,很多高并发场景借鉴了Disruptor的设计,减少竞争的强度。其设计思想可以扩展到分布式场景,通过无锁设计,来提升服务性能。
使用Disruptor比使用ArrayBlockingQueue略微复杂,为方便读者上手,增加代码样例。
代码实现的功能:每10ms向disruptor中插入一个元素,消费者读取数据,并打印到终端。详细逻辑请细读代码。
参考文档
- http://brokendreams.iteye.com/blog/2255720
- http://ifeve.com/dissecting-disruptor-whats-so-special/
- https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results
- https://lmax-exchange.github.io/disruptor/
- https://logging.apache.org/log4j/2.x/manual/async.html
- 原文地址:https://tech.meituan.com/2016/11/18/disruptor.html
评论区